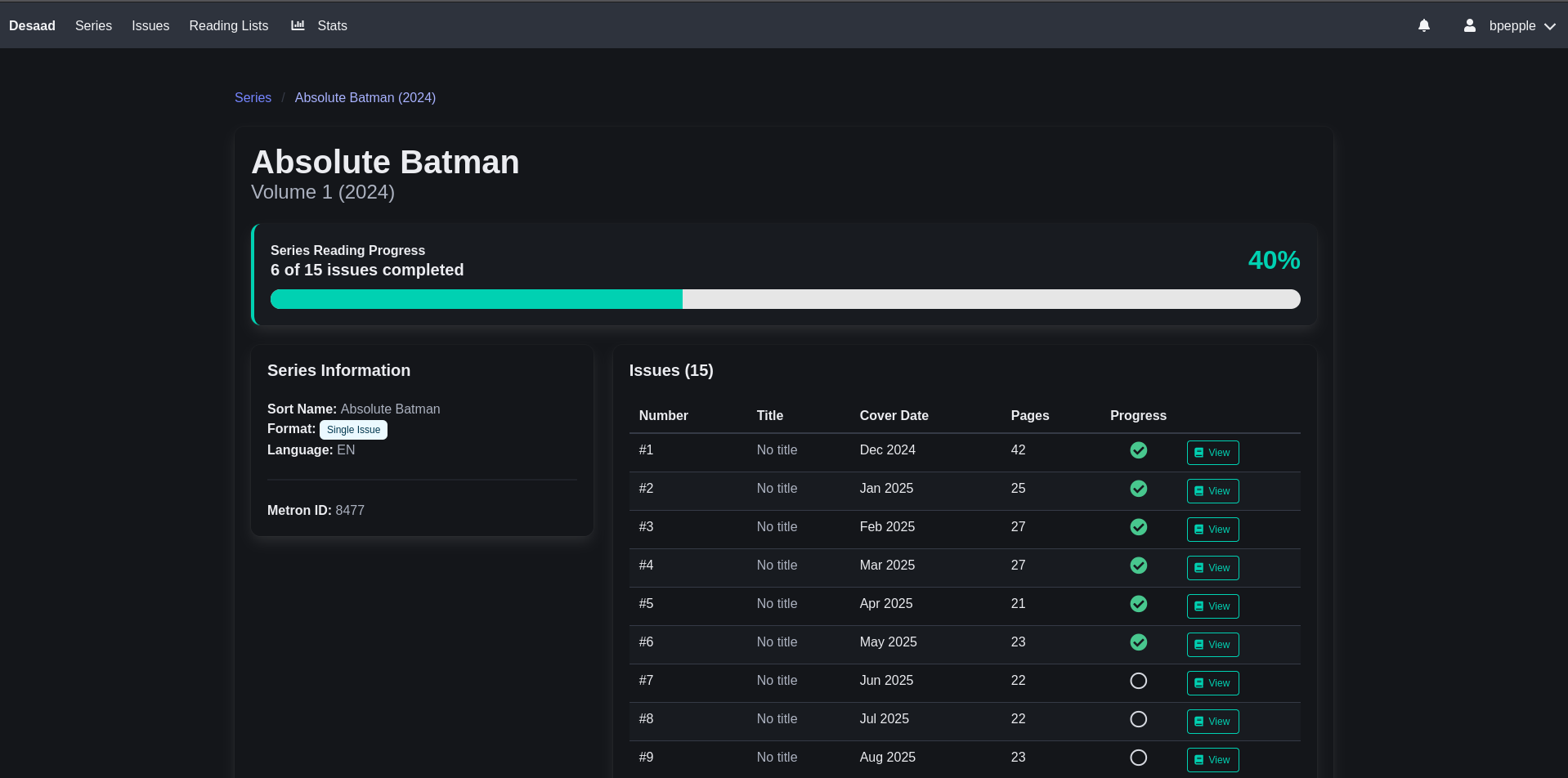
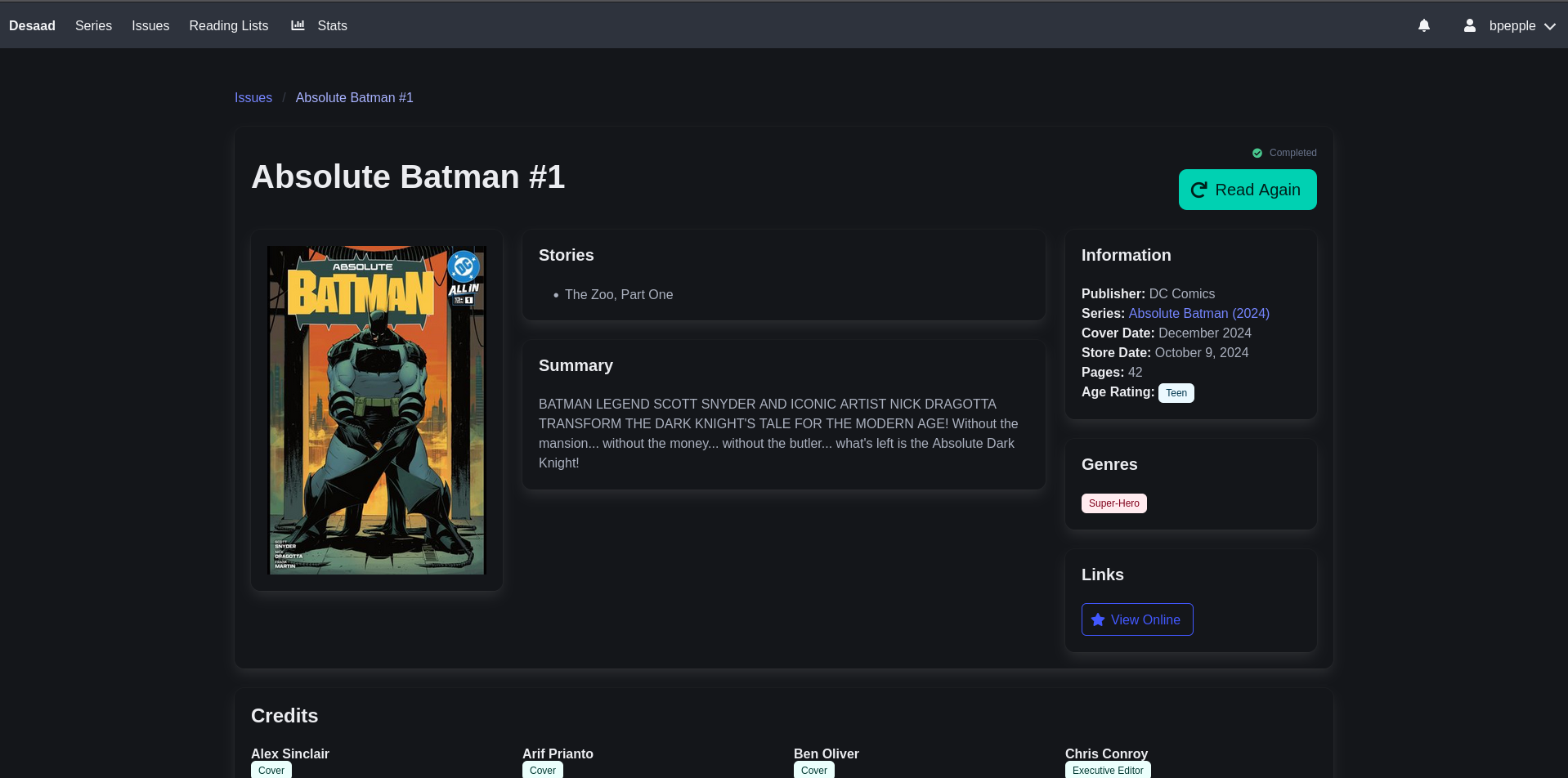
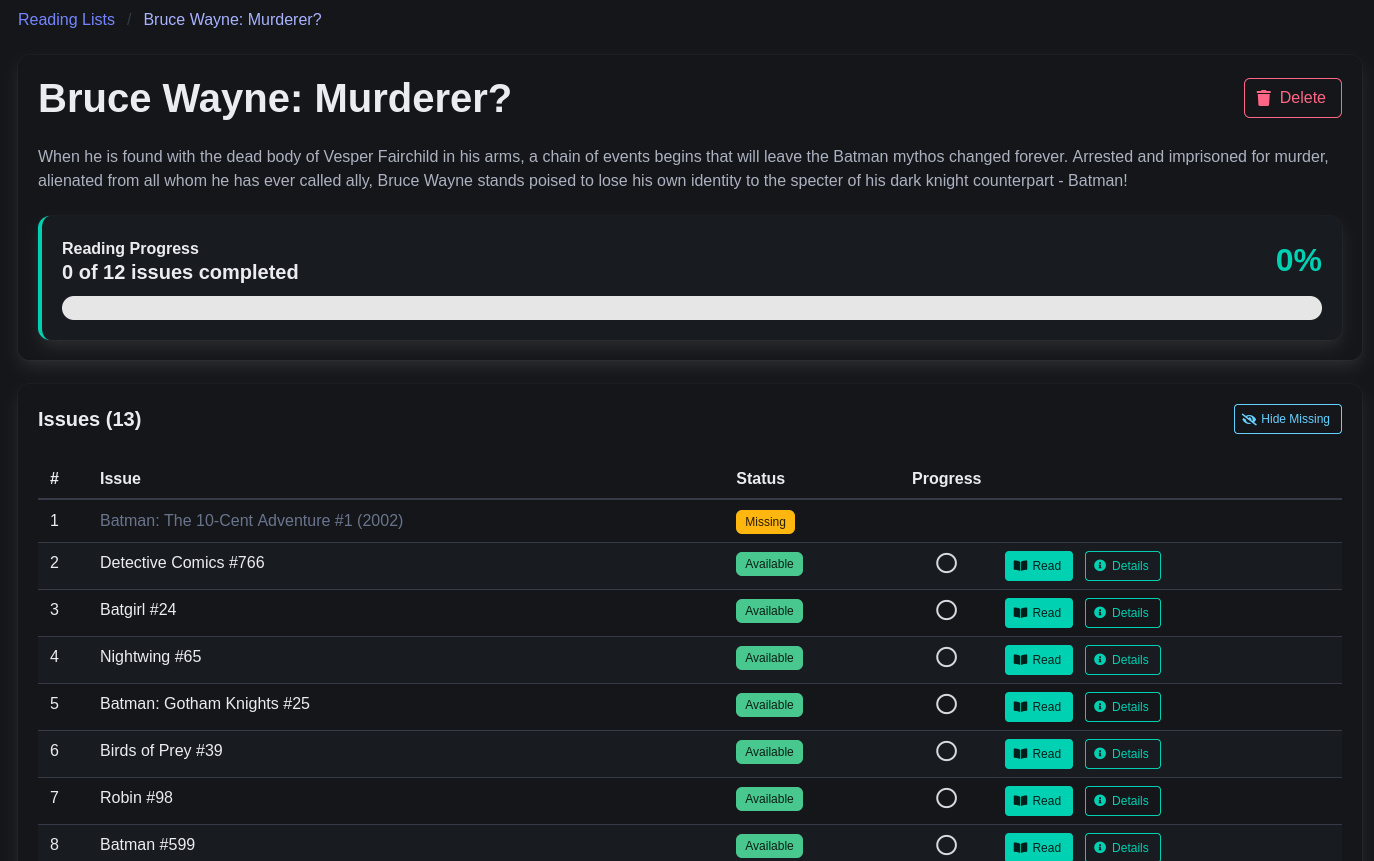
February 2026 News

Monthly Statistics
During February the Metron Project added the following to its database:
- Users: 152
- Issues: 1,357
- Creators: 246
- Characters: 678
Thanks to everyone that contributed!
API Usage
Over the last 6 months, API usage has seen a significant increase — which is great! However, we are now at a point where our current server capacity is being strained.
Jonas Stendahl and I have landed some optimizations in the site's code, but they only go so far in relieving the pressure.
That leaves us with two options:
- Upgrade our server capacity — an additional $27–$43/month depending on the CPU tier selected.
- Reduce the daily rate-limit from 10,000 requests to something like 5,000.
Option #1 is clearly preferable, but we currently don't receive enough donations to cover the extra cost. That means we will likely need to reduce the daily rate-limit in the very near future, and we'll post an announcement here when that happens.
If you have other ideas or suggestions, please reach out!
Website Updates
Performance Improvements
Several changes were made to improve API and database query performance.
- API query optimization: Refactored multiple API endpoint viewsets to reduce unnecessary database queries through better use of
select_relatedandprefetch_related. - Additional database indexes: Added missing indexes on several models (Publisher, Series, Team, Universe) and their related issue querysets, which should speed up common lookups. (jyggen)
- Fixed paginated Series queryset warning: Added explicit
order_by()toSeriesViewSetand the publisher series-list action to resolve aUnorderedObjectListWarningthat could surface during pagination.
API Enhancements
- Conditional request support: The API now supports HTTP conditional requests using
ETagandLast-Modifiedheaders. Clients can sendIf-None-MatchorIf-Modified-Sinceheaders to avoid re-downloading unchanged data, saving bandwidth. (jyggen) - Read dates in collection API: The collection list endpoint now includes
read_datesdata, giving API consumers access to reading history information directly from the list view.
Collection & Reading History
- Reading history charts: The Collection Statistics page now includes daily (last 30 days) and monthly (last 12 months) column charts showing reading activity over time. Days with no reading activity are included in the daily chart.
- Refined badge display logic: The read-count badge is now only shown when an issue has been read multiple times on the same calendar day, avoiding misleading counts from reads on different days.
User Interface Fixes
- ESC key closes cover modal: On issue detail pages, pressing the Escape key now closes the cover image modal, matching standard UX conventions.
- Variant formset display tweaks: Minor layout improvements to the variant issue formset to better display its fields.
- User template improvements for editors: The user profile template now shows additional information for editors.
- Series form validation fix: Handled a case where a missing series type would cause an unhandled error during form validation.
Other
- Django 5.2.11 (#454): Updated to the latest Django 5.2 patch release.
Mokkari Updates
The following changes made to Mokkari, the Python wrapper for the Metron API, over the past month:
Added if_modified_since parameter to detail endpoints
All the detail methods (arc, character, creator, imprint, issue, publisher, series, team, universe, reading_list, and collection) now accept an optional if_modified_since datetime parameter. When provided, the request includes an If-Modified-Since HTTP header (formatted per RFC 7231) and returns None on a 304 Not Modified response — useful for efficiently detecting whether a resource has changed since you last fetched it. Naive datetimes are treated as UTC, and non-UTC datetimes are automatically converted before the header is sent.
Added Read Dates to CollectionList schema
The collection schemas have been updated to match the latest Metron API:
- A new
ReadDatemodel was added withid,read_date, andcreated_onfields. read_datesandread_countfields were added toCollectionListandCollectionRead.- The
date_readfield type inCollectionReadwas changed fromdatetodatetimeto align with the API's date-time format.
Migrated to PyrateLimiter 4.x
The rate-limiting implementation was updated for the breaking changes in pyrate-limiter 4.0:
- Removed the now-deleted
BucketFullExceptionandLimiterDelayExceptionimports. - Simplified
Limiterconstruction. - Rewrote
_check_rate_limit()to use the boolean return value oftry_acquire(blocking=False)instead of catching exceptions.
Desaad Update
Here's a roundup of changes shipped to Desaad over the past month.
Reading History Import
The import_reading_status management command was upgraded: it now imports reading history dates from Metron, not just reading status. A new
ReadDate model was added to store the actual date an issue was read, and the UserStatsView was updated to use these dates for reading activity stats. Previously, stats reflected the import timestamp rather than when issues were actually read.
Importer: Require External IDs
The comic importer was tightened up to require an external ID when creating characters, teams, universes, arcs, locations, genres, and creators. Previously, the importer would fall back to name-based lookups and create records without a verified external ID, leading to potential unverified duplicates. This change simplifies the importer significantly and ensures all entities can be reliably matched against a metadata source.
Reader UX: Double-Tap Confirmation
The comic reader's Prev Issue, Next Issue, and Close buttons now require a double-tap to activate. On the first tap, the button turns yellow and prompts "Tap again"; a second tap within 2 seconds proceeds with navigation. Otherwise, the button resets. This prevents accidental navigation away from your current reading position.
Infrastructure Updates
- Python 3.14: The container image was updated to use Python 3.14.
- Timezone via environment variable: The Django timezone setting is now configurable via an environment variable. Missing
DB_*variables were also documented in the README. - Dependency updates: Project dependencies were refreshed across the board.
OpenCollective
A huge thank you to everyone who has contributed to our Open Collective! Your support makes a real difference in keeping the Metron Project running and growing.
What Your Contributions Support
Funds from Open Collective go directly toward:
- Server hosting costs - Keeping the Metron website and API available
- Domain registration - Annual domain name renewals
- Future capacity increases - Scaling resources as the database and user base grows
All expenses are transparent and publicly viewable on our Open Collective page, so you can see exactly where every dollar goes.
Support the Project
If you'd like to help keep the lights on and support continued development, contributions of any size are appreciated and help ensure Metron remains a free resource for the comic book community.
Anyway, that's everything for this month! Take care.